

Asset owners face numerous data management challenges, particularly relating to ingesting and analysing data on private markets. As it turns out, several of our clients are grappling with exactly this problem, so we decided to see whether generative AI might be able to help, by conducing a proof-of-concept to determine whether we could solve a very specific problem in investment operations.
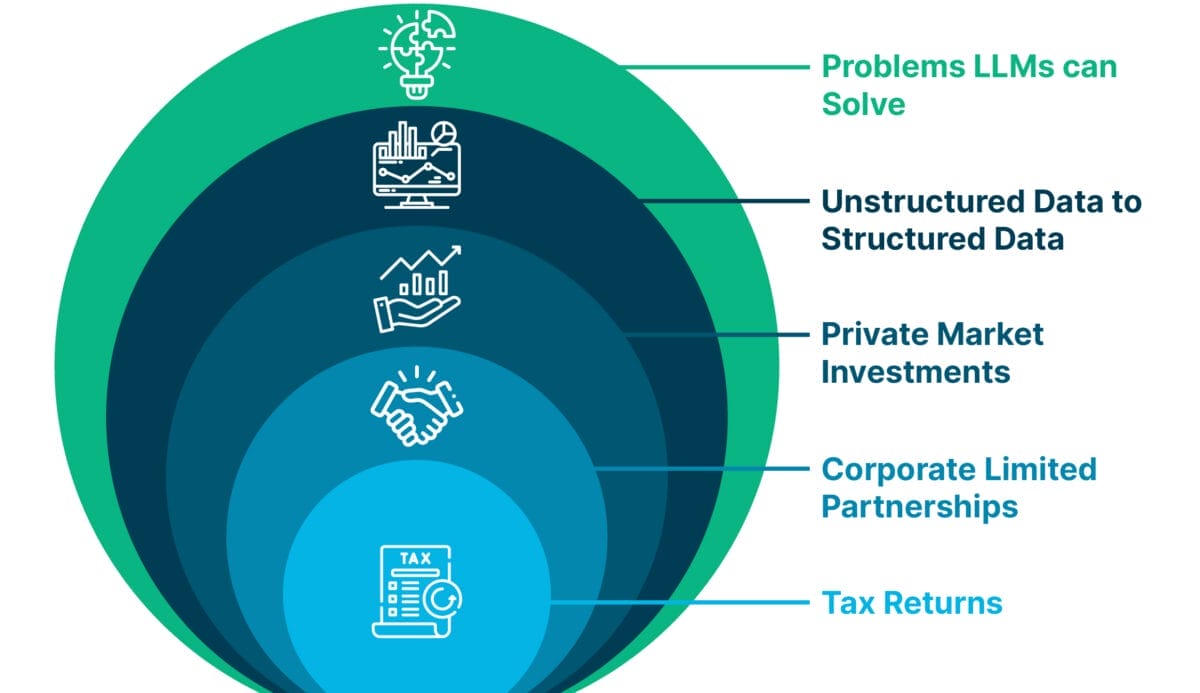
To limit the scope of the proof-of-concept (PoC) we focused on one specific type of private market investment – corporate limited partnerships – and on one use case for data relating to those investments – populating tax returns. Ultimately, the PoC was a success, and along the way we learnt a few things about working with generative AI to solve problems in financial services.
Going into the PoC, our hypothesis was that we could use optical character recognition (OCR) and a large language model (LLM) to extract data from inconsistently formatted PDF documents and use it to populate a tax return. OCR is a mature and largely proven technology, so the focus of the PoC was the LLM.
We planned to use an existing LLM (think ChatGPT), and considered some combination of three approaches for getting that LLM to do what we wanted:
- Prompt engineering: writing and refining the kinds of instructions the average person uses to interface with ChatGPT and other LLM chatbots.
- Retrieval-augmented generation (RAG): a family of methods for making an external knowledge base available to an LLM.
- Fine tuning: essentially retraining an LLM on a domain-specific dataset.
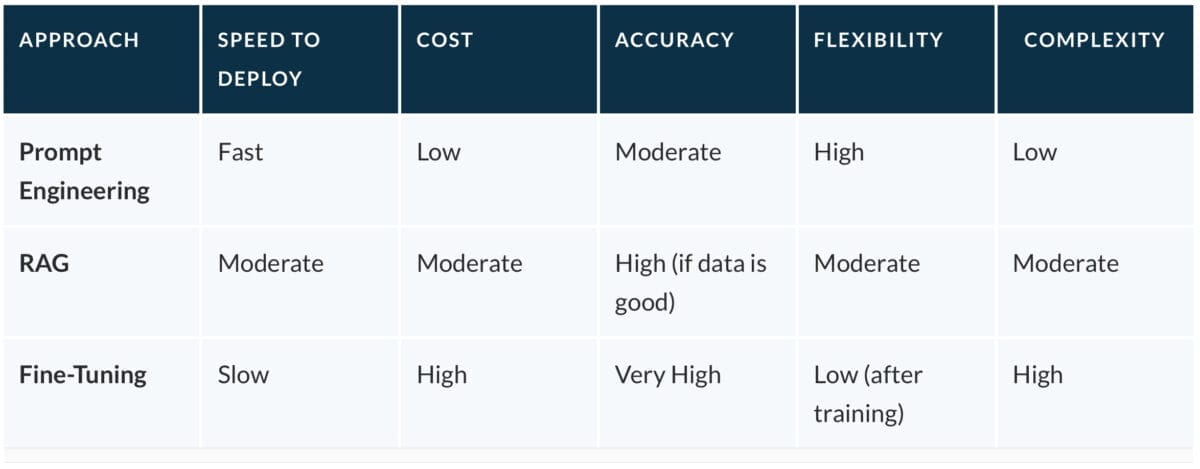
Ultimately, we ended up getting good results by using RAG solely to make the data from the PDFs available to the LLM and otherwise doing as much as possible through prompt-engineering.
Towards the end of the PoC we debated the intellectual property consequences of preferencing prompt-engineering over fine tuning as a means for improving accuracy. A bit of cursory research seemed to indicate that a fine-tuned LLM would be more defensible as proprietary IP than an extensive set of prompts but given the lack of precedent, this is far from certain.

Technology is evolving so quickly
As with many aspects of generative AI, the technology is evolving so quickly that everything around it – including the law – is playing catch up, which bring us to our next lesson.
Boy, is progress happening at pace in generative AI. Even as we were working on the proof-of-concept, new methods were being developed and new tooling becoming available. To give just a few examples:
- Retrieval Augmented Fine Tuning (RAFT): a preprint research paper by a team from the University of California, Berkeley described a method for combining elements of RAG with fine tuning. As mentioned before, RAG allows an external knowledge base to be incorporated into an LLM query. In essence, RAFT uses fine tuning to train an LLM to be more discerning about what information is drawn on from that knowledge base, and how it gets incorporated into its responses.
- OpenAI o3: OpenAI recently released their latest and greatest model, which represents a significant improvement on what was previously the best model available through ChatGPT and Azure APIs.
- Agentic AI: this seems to be the AI buzzword of the summer. Agentic AI is being used to refer to a combination of LLMs, more traditional machine learning methods, and good ol’ enterprise automation to yield autonomous agents capable of taking independent actions and pursuing multi-step goals.
Seeing all of this leads naturally to questions about how best to proceed. Should you wait until a particular technology or toolset stabilises before you use it to build solutions? Should you be constantly migrating to the latest and greatest methods and technologies? Should you just decide it’s all too risky and wait until someone else builds what you or your clients are looking for?
Go for it
Ultimately, we concluded that, provided the tooling you’re using can solve the business problem you’ve identified, you should go for it. Keeping abreast of developments is important, and where you can use new tools and tech to improve your solutions this is worth considering. But as always, the perfect should not be the enemy of the good.
Generative AI makes mistakes. It has a tendency to make things up, and it struggles with certain kinds of logic. It still can’t help us with the cryptic crossword.
Given that we wanted it to do something where errors really can’t be tolerated, that is, populating a tax return, we had to establish a way we could trust what the model was telling us.
We did this by configuring the solution to document the provenance of the data it was using to populate a given tax return.
In practice this means that it specifies where it sourced a piece of information from, to the precision of a specific section or table in a particular document. This does not eliminate the risk or error; the AI could still interpret the document incorrectly or even hallucinate the provenance. What it does, however, is make it quick and easy for a human to check the AI’s work.
For a business problem like this one, where tolerance for errors is low, having a human involved for quality control purposes is still crucial. Forcing AI to document provenance allows that to be done in a minimally labour-intensive way.
Lots to learn, lots to gain
As we move from a successful PoC into implementing a production-grade solution, there will no doubt be more lessons to learn. Generative AI might not yet be perfect, but when paired with thoughtful implementation and human oversight, we are beginning to see its potential to solve real-world problems in financial services.
Use cases like this one ultimately benefit end-customers – every optimised or automated process either brings costs down or allows the redeployment of resources to provide a higher quality service.
To realise these benefits, the key is to start where the technology is today and improve as it evolves–because waiting for perfection could mean missing out on significant gains.
Kevin Fernandez is general manager, market strategy and propositions, at Novigi











Leave a Comment
You must be logged in to post a comment.